Referencing CDS Tables
A variable that is able to reference time series data through a vector can also reference a CDS.
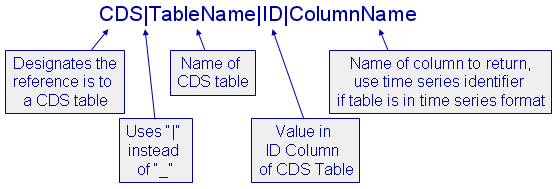
The format for this vector type is as follows: CDS|TableName|ID|ColumnName (or time series like YR). In this format CDS designates the vector is pointing to a CDS Table. The TableName should be the name of the CDS table. The ID should be a unique value in a column named “ID” found in the CDS table. The ColumnName can be one of two things, either the actual column name where the data exists in the CDS table or one of the time series identifiers (YR, MN, WK, or HR). Refer to the illustration below:
![]() NOTE: The ID column in a CDS table is a primary key and must be unique. The ID column cannot be a computational column nor contain an expression.
NOTE: The ID column in a CDS table is a primary key and must be unique. The ID column cannot be a computational column nor contain an expression.
![]() NOTE: References to the Time Series Generic table are not allowed.
NOTE: References to the Time Series Generic table are not allowed.
To use a time series identifier in the ColumnName position of the CDS vector the appropriate columns relative to the time series are required to exist in the CDS table. For the YR identifier columns which contain the relative years (2005, etc.) must be present as in the Time Series Annual Table. For the MN identifier columns which contain the relative months (1-12) must be present as in the Time Series Monthly Table. For the WK identifier columns which contain the relative weeks of the year (1-168) must be present as in the Time Series Weekly Table. For the HR identifier the columns “Date”, “Hour” and “Data” which contain the relative data must be present as in the Time Series Hourly Table. See Example below.
Not only can a CDS vector be used in a typical data table such as the Resources or Fuel tables but it may also be used as a pointer in the time series tables. Additionally, a typical time series vector (YR_, MN_, etc.) may also be used in a CDS table. For example, an annual reference (YR_) can be used from an Input Table to point to the Time Series Annual Table. Then in the Time Series Annual Table can use a CDS vector to point to a CDS table.
When a CDS Table is referencing a Memory Table, the CDS Table can be updated based on a time interval during a run. This means input data may be modified during a run based upon results in the Memory Table. These updates may occur down to an hourly basis.
The Input Refresh Frequency column in the Computational Datasets window contains a dropdown containing the following options:
|
Start Pre Hourly Pre Daily Pre Monthly Pre Yearly Pre Study |
Hourly Daily Monthly Yearly Study |
Start & Hourly Start & Daily Start & Monthly Start & Yearly Start & Study |
Based upon the selection, the table will update with the latest available data.
![]() NOTE: The benefit of the "Pre" options in the Input Refresh Frequency drop down is to greatly improve the run time performance when the input updates are based upon information that is known prior to the time period being dispatched (e.g. risk_iteration, generic risk draw, dispatch_hour, etc.)
NOTE: The benefit of the "Pre" options in the Input Refresh Frequency drop down is to greatly improve the run time performance when the input updates are based upon information that is known prior to the time period being dispatched (e.g. risk_iteration, generic risk draw, dispatch_hour, etc.)
Example
In this example, the CDS table has a structure that matches a time series table (annual, monthly, weekly, hourly). Let's say you would like a cell/value in one of the other input database tables to reference that data. For instance, you have some annual gas prices you wanted to reference using this approach. Here is an example of what the CDS table may look like:

You could reference these values in the price column in the Fuels table for the Fuel ID=NGHenry with the following CDS reference: CDS|HenryHub_AnnualPrice|HenryHubPrice|YR. It would look something like this:
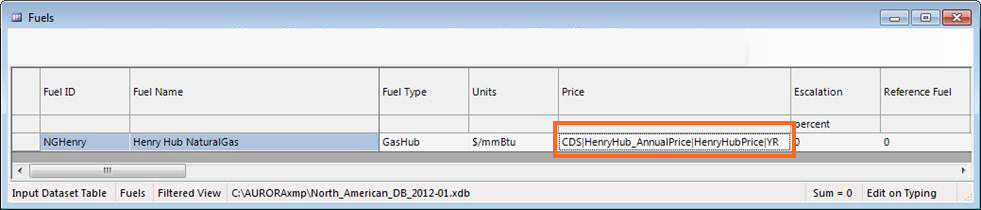
As Aurora runs, it would pick up the prices for the appropriate year from the CDS table. This basically replicates the standard time series functionality but lets you do so with the added flexibility of computational datasets.
![]() Working With CDS Tables
Working With CDS Tables
![]() References CDS Tables
References CDS Tables